|
Ph.D. Student, Beihang University Email: yuanbobuaa@buaa.edu.cn [Google Scholar] |
|---|
Biography
Bo Yuan received the B.S. and M.S. degrees from Beihang University in 2019 and 2022, respectively, where he is currently pursuing the Ph.D. degree supervised by Prof. Danpei Zhao. From 2020 to 2021, he was a Research Intern at ByteDance AI-Lab. His research interests include machine learning, computer vision, life-long learning, and their application in remote sensing images. He has authored papers in refereed journals and proceedings, including IEEE Transactions on Pattern Analysis and Machine Intelligence, IEEE Transactions on Image Processing, IEEE Transactions on Geoscience and Remote Sensing, ACM MM, etc. He serves as a Student Member for the China Society of Image and Graphics.
Recent news
- [2025.08] One paper published in IEEE TGRS.
- [2025.03] One paper published in IEEE TGRS.
- [2025.01] One paper published in IEEE TGRS.
- [2024.10] One paper published in ACMMM 2024.
- [2024.08] One paper published in IEEE TPAMI.
- [2024.05] One paper published in IEEE TPAMI.
- [2024.04] Two papers published in IEEE TGRS.
- [2023.12] One paper published in IEEE TGRS.
- [2023.10] A Survey of Continual Semantic Segmentation has been released here!
- [2023.05] One paper published in IEEE TPAMI.
- [2022.03] One paper published in IEEE TIP.
- [2021.11] One paper published in IEEE GRSL.
Publications
2025
Dual-Stream Spectral Decoupling Distillation for Remote Sensing Object Detection - IEEE Transactions on Geoscience and Remote Sensing, 2025.
Xiangyi Gao, Danpei Zhao, Bo Yuan, Wentao Li
RescueADI: Adaptive Disaster Interpretation in Remote Sensing Images With Autonomous Agents - IEEE Transactions on Geoscience and Remote Sensing, 2025.
Zhuoran Liu, Danpei Zhao, Bo Yuan, Zhiguo Jiang
Reconciling Semantic Controllability and Diversity for Remote Sensing Image Synthesis with Hybrid Semantic Embedding - IEEE Transactions on Geoscience and Remote Sensing, 2025.
Junde Liu, Danpei Zhao, Bo Yuan, Wentao Li, Tian Li
2024
Continual Panoptic Perception: Towards Multi-modal Incremental Interpretation of Remote Sensing Images - ACMMM 2024.
Bo Yuan, Danpei Zhao, Zhuoran Liu, Wentao Li, Tian Li
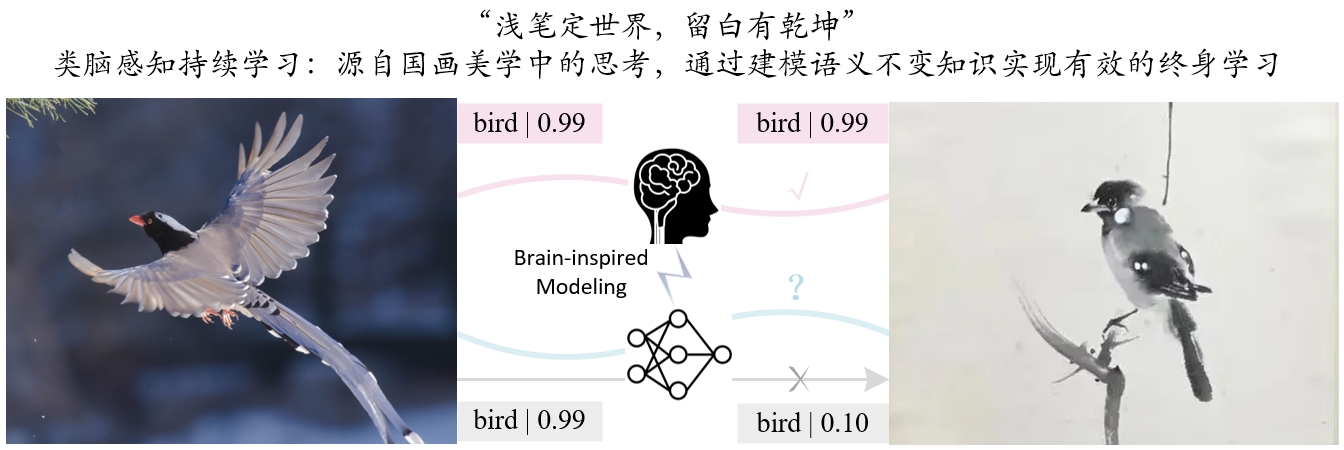
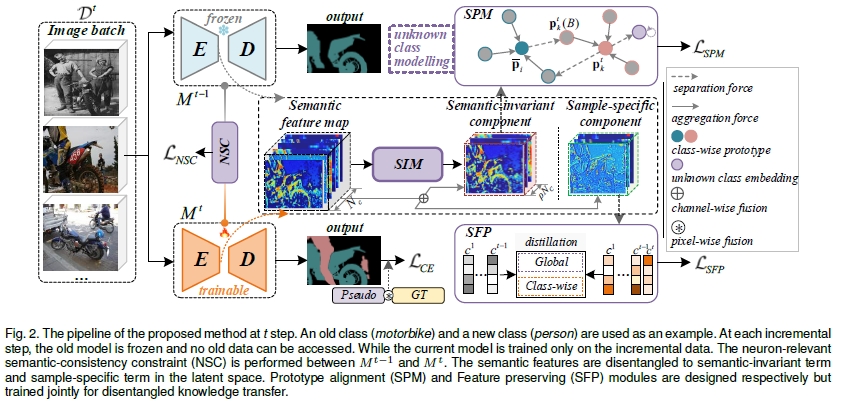
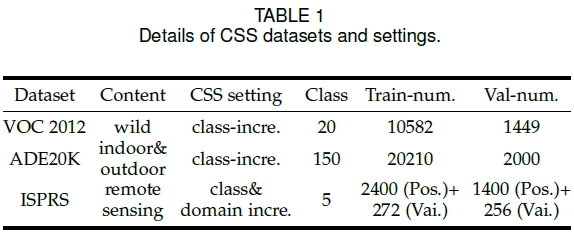
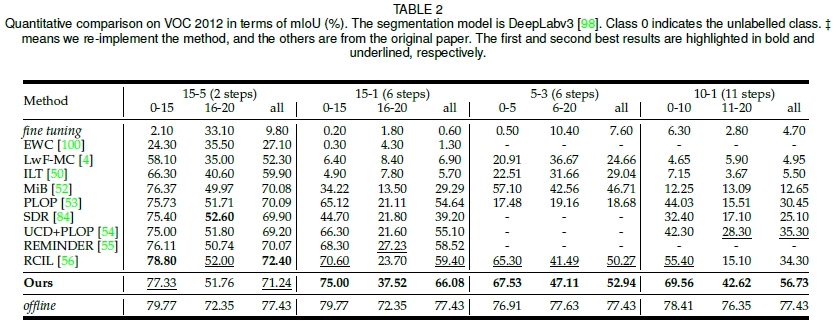
Learning at a Glance: Towards Interpretable Data-limited Continual Semantic Segmentation via Semantic-Invariance Modelling - IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
Bo Yuan, Danpei Zhao, Zhenwei Shi
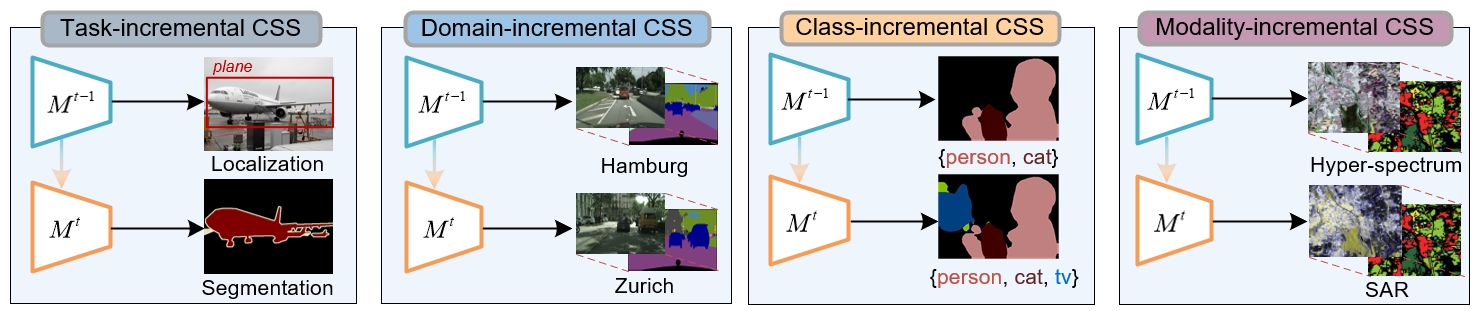
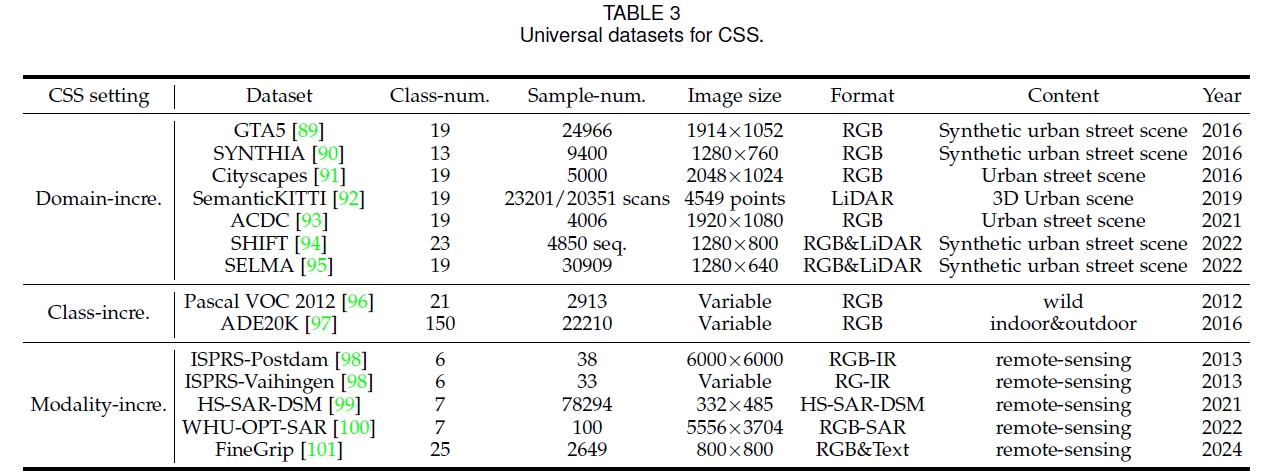
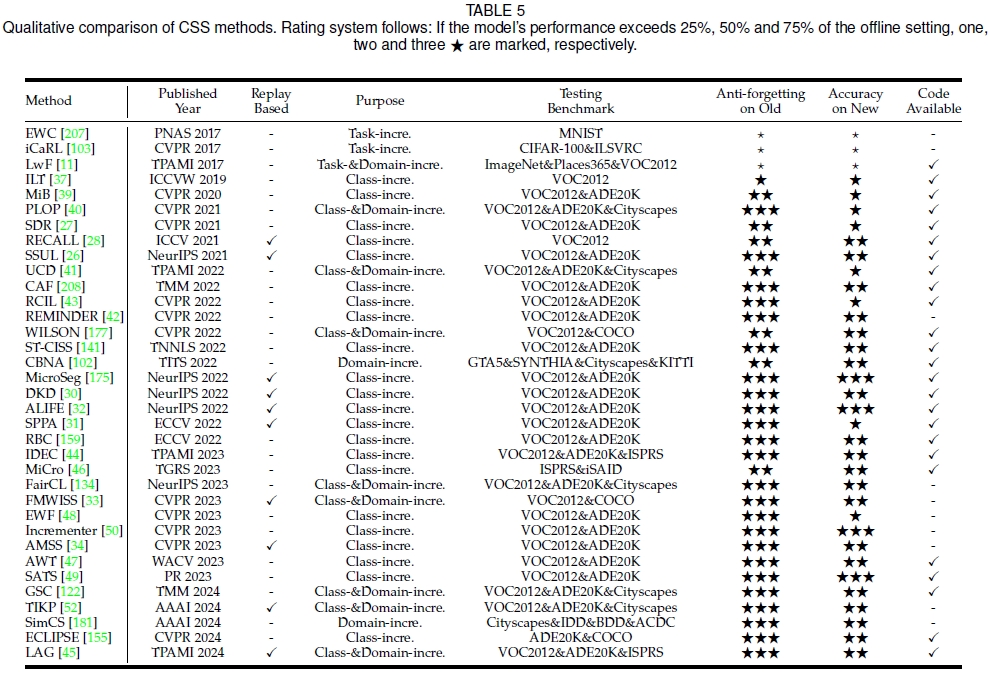
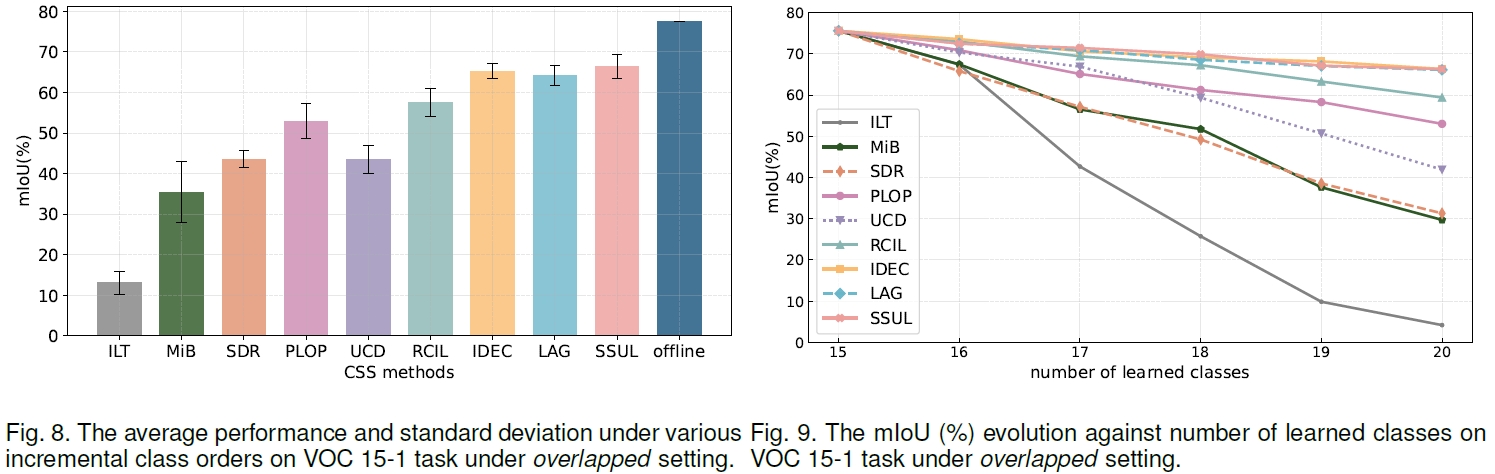
A Survey on Continual Semantic Segmentation: Theory, Challenge, Method and Application. - IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024.
Bo Yuan, Danpei Zhao
[Project Page]
Panoptic Perception: A Novel Task and Fine-grained Dataset for Universal Remote Sensing Image Interpretation - IEEE Transactions on Geoscience and Remote Sensing, 2024
Danpei Zhao, Bo Yuan, Ziqiang Chen, Tian Li, Zhuoran Liu, Wentao Li, and Yue Gao
[Project Page]
TopoNAS: Boosting Search Efficiency of Gradient-based NAS via Topological Simplification
Danpei Zhao, Zhuoran Liu, Bo Yuan
See, Perceive and Answer: A Unified Benchmark for High-resolution Post-disaster Evaluation in Remote Sensing Images - IEEE Transactions on Geoscience and Remote Sensing, 2024
Danpei Zhao, Jiankai Lu, Bo Yuan
2023
Inherit with Distillation and Evolve with Contrast: Exploring Class Incremental Semantic Segmentation without Exemplar Memory.
Danpei Zhao, Bo Yuan, Zhenwei Shi. - IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
PETDet: Proposal Enhancement for Two-Stage Fine-Grained Object Detection - IEEE Transactions on Geoscience and Remote Sensing, 2023
Wentao Li, Danpei Zhao, Bo Yuan, Yue Gao, Zhenwei Shi
2022
Birds of a Feather Flock Together: Category-Divergence Guidance for Domain Adaptive Segmentation.
Bo Yuan, Danpei Zhao, Shuai Shao, Zehuan Yuan, Changhu Wang. - IEEE Transactions on Image Processing, 2022.
2021
UGCNet: An Unsupervised Semantic Segmentation Network Embedded With Geometry Consistency for Remote-Sensing Images.
Danpei Zhao, Bo Yuan, Yue Gao, Xinhu Qi, Zhenwei Shi - IEEE Geoscience and Remote Sensing Letters, 2021.
V2RNet: An unsupervised semantic segmentation algorithm for remote sensing images via cross-domain transfer learning.
Danpei Zhao, Jiayi Li, Bo Yuan, Zhenwei Shi. - IEEE International Geoscience and Remote Sensing Symposium IGARSS, 2021.
Selective focus saliency model driven by object class‐awareness
Danpei Zhao, Bo Yuan, Zhenwei Shi, Zhiguo Jiang. - IET Image Processing, 2021
2018
No-reference blurred image quality assessment by structural similarity index
Haopeng Zhang, Bo Yuan, Bo Dong, Zhiguo Jiang. - Applied Sciences, 2018.
Links
Research Collaborators:
[Danpei Zhao (赵丹培)] [Shuai Shao (邵帅)]