Theory, Challenge, Method and Application
摘要
持续学习,又称为增量学习或终身学习,打破传统深度学习方式在闭集上进行训练和推理的限制,使模型能够在开放数据集上进行连续自适应学习。在过去的十年中,持续学习已在多个领域得到广泛探讨和应用,尤其是在计算机视觉领域,包括分类、检测和分割等任务。而持续语义分割(CSS)由于其密集预测的特殊性质,成为了一个充满挑战、复杂且不断发展的任务。在本文中,我们对CSS进行了综述,涵盖了持续语义分割的问题定义、主要挑战、通用数据集、方法理论和应用的全面调研。根据是否需要存储部分旧数据,本文将当前的CSS模型分为data-replay和data-free两大类。本文对现有的CSS方法进行了调研、分类和比较,并在相关数据集上的定性和定量对比。
方法分类
根据持续语义分割的场景,我们还把CSS任务分为了四种,分别是任务增量(Task-incremental CSS)、领域增量(Domain-incremental CSS)、类别增量(Class-incremental CSS)和模态增量(Modality-incremental CSS)。这四种任务涵盖了持续语义分割多样化的应用场景和发展趋势。此外,本文还建立了一个CSS基准,其中包括代表性文献、评估结果和复制实验,仓库已经开源。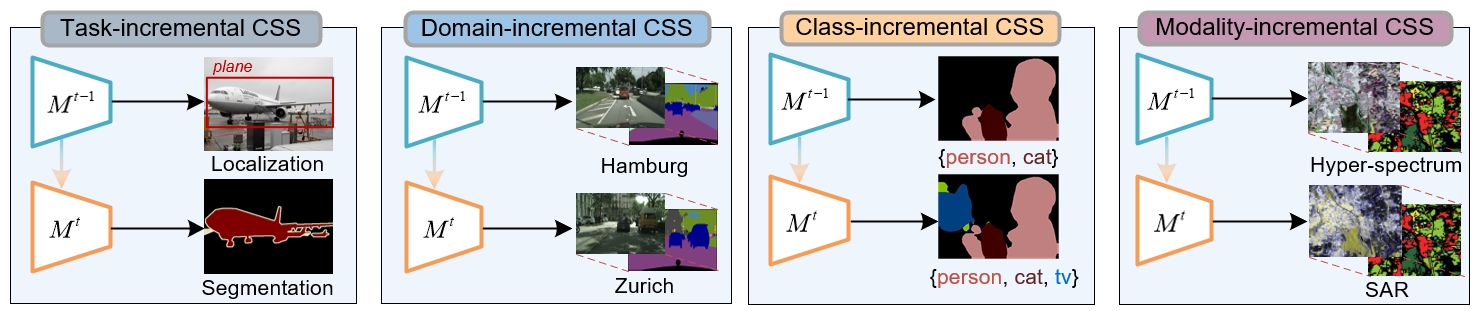
如下图所示,根据是否需要存储和回放旧知识,CSS可以分为基于回放的方法(Data-Replay)和不依赖旧数据的方法(Data-Free)两类。
- Data-replay方法
其中基于回放的方法又可以分为代表性数据回放(Exemplar-replay)和生成式回放(Generative-replay)两种。
代表性数据回放:这类方法通过存储部分旧类别的数据,并在增量训练的过程中和新增数据共同监督模型训练,以减少对旧类别的灾难性遗忘。根据数据回放的方式,可以分为样本回放(sample-reply)、特征回放(feature-replay)和辅助数据(Auxiliary data)的方式。其中样本回放就是直接存储原始图像;特征回放的方式通常保存类别特征原型;辅助数据则可以通过从一个易获取的渠道(例如从互联网)获取大量数据辅助模型增量训练。数据回放的原则主要包括以下几种方式:包括:1)类别平衡原则;2)损失函数值原则;3)熵原则;4)梯度原则;5)表征原则。
生成式数据回放:由于实际场景中,直接存储旧类别数据会面临隐私限制和存储空间开销的问题,这类方法通过生成与旧类别一致的图像实现数据回放。代表性方法是RECALL-GAN。
- Data-free方法
而不依赖旧数据的方法具有更加明显的应用优势,不需要额外的存储空间开销,也无需保留特征原型,仅依靠模型本身实现增量更新。目前的方法可以分为基于自监督的方法(Self-supervised)、基于正则化的方法(Regularization-based)和基于动态结构的方法(Dynamic-architecture)。
- 基于自监督的方法:通常利用对比学习(代表方法包括SDR、UCD、IDEC等)、伪标注生成(代表方法包括ProCA、REMINDER)、基础模型驱动(代表方法包括FMWISS)等方式获取旧类别的监督信息,辅助模型训练。
- 基于正则化的方法:通常采用知识蒸馏(如MiB、PLOP、IDEC)、预训练(如MicroSeg)和权重迁移(如SWT、GSC、SimCS)的方式更新模型参数。
- 基于动态结构的方法:通过参数分割(如ACD、FairCL)、模型分解(如RCIL、DKD)和模块化网络设计实现模型的结构更新。
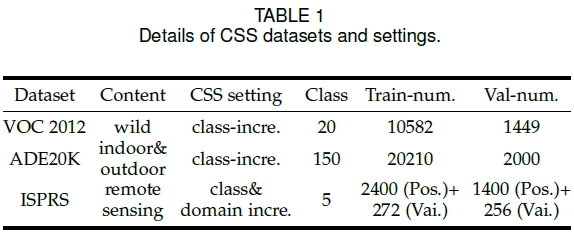
数据集
下表列出了持续语义分割任务常用的数据集。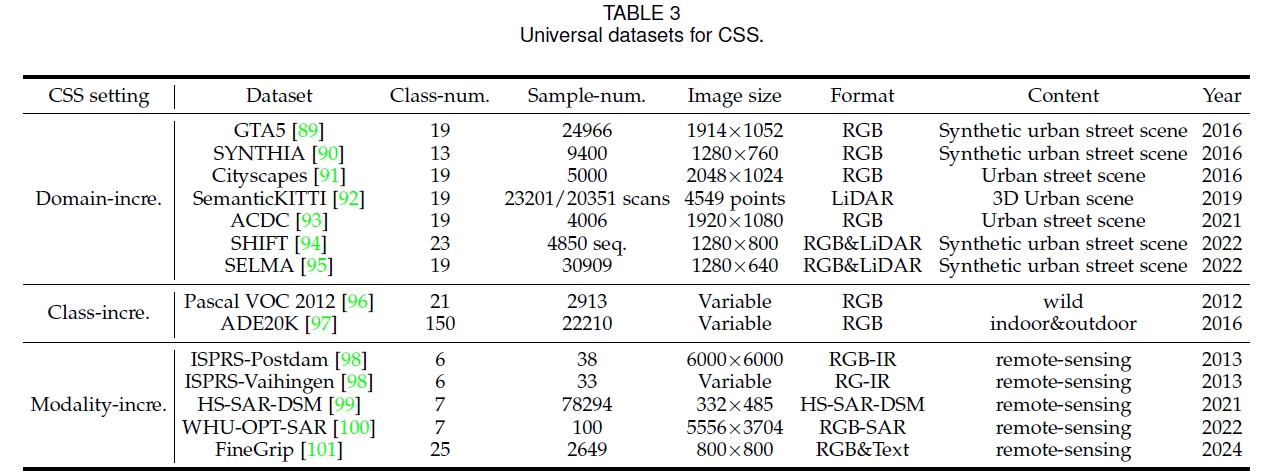
性能评估
- 定性对比
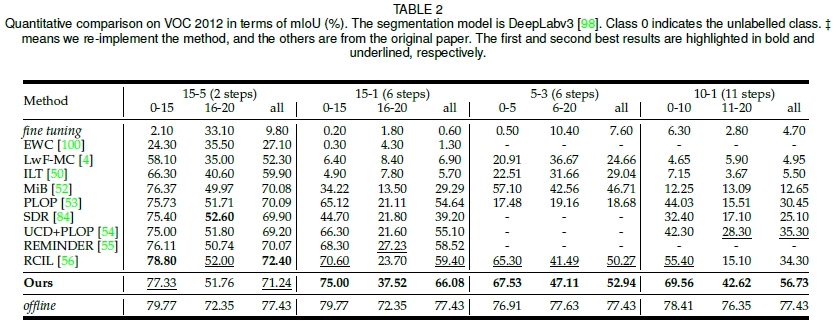
下表展示了近年来CSS模型的各项特性,包括发表时间、任务属性、测试数据集、模型性能等多方面因素。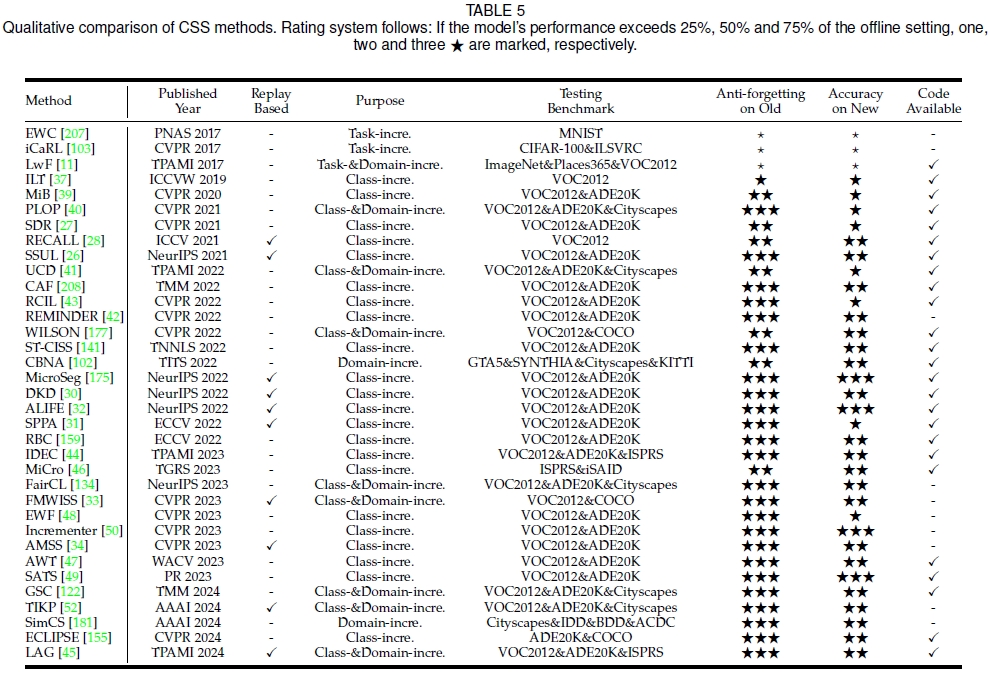
- 定量对比
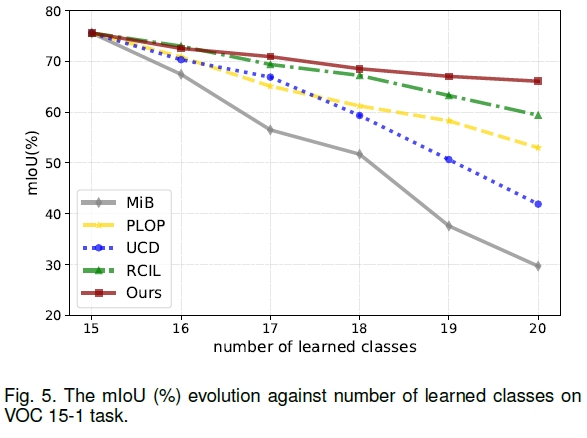
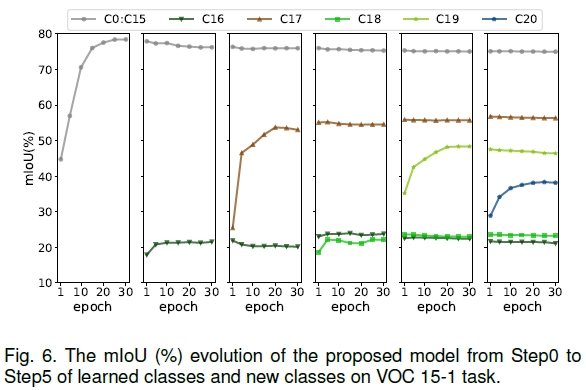
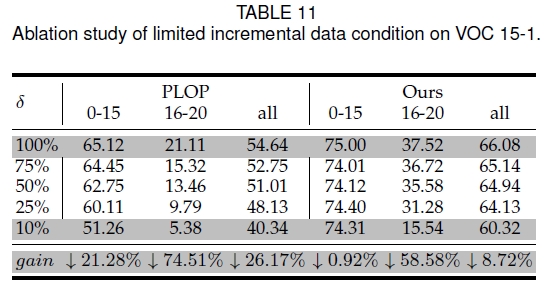
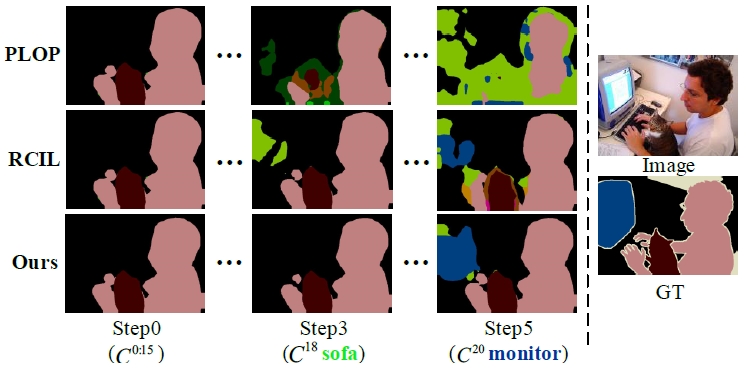
下图展示了9种代表性算法的性能对比,包括学习顺序稳健性、抗遗忘能力等。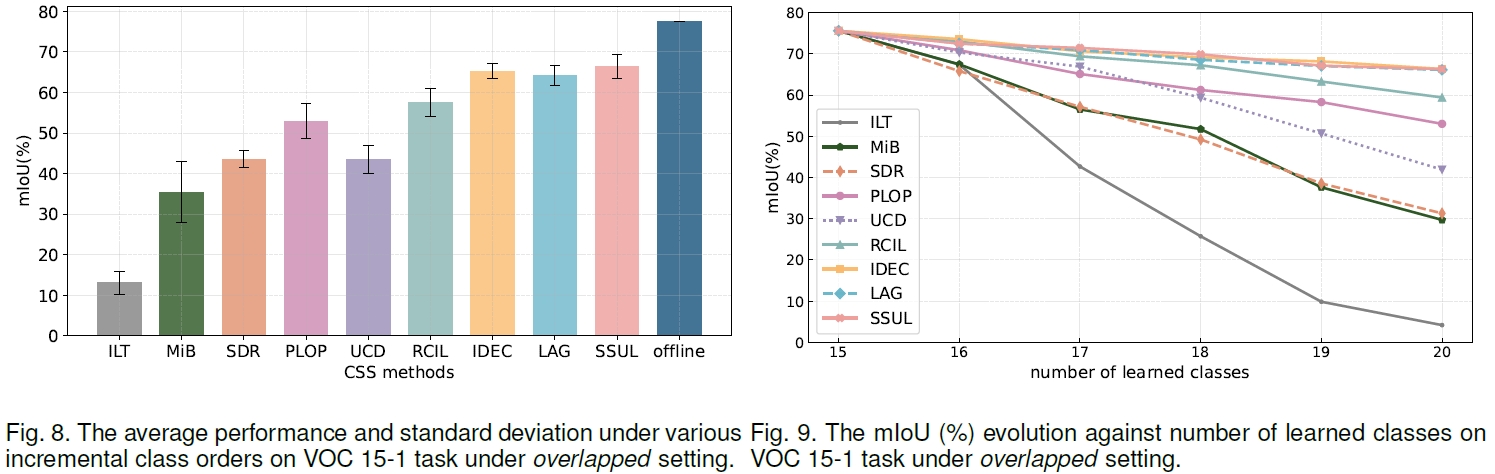
总结
持续语义分割(CSS)使模型能够在动态和开放的环境中不断学习新知识,同时保持对现有知识的保留,从而在稳定性和可塑性之间取得平衡。持续学习技术有望模仿人类的学习模式,对于构建强人工智能,扩展其应用领域,提高深度学习模型的智能化水平具有重要价值。我们希望这篇综述能够为相关领域的研究者提供一些有价值的参考。
© 2024 Bo Yuan All Rights Reserved